Links: University
T2 Diseño lógico
Reglas de inferencia
Regla reflexiva
Si X contiene Y, entonces {X}→{Y}
Regla de aumento
{X}→{Y} |= {XZ}→{YZ}
{X}→{Y} |= {XZ}→{Y}
Regla transitiva
X}→{Y},{Y}→{Z |= {X}→{Z}
Regla de descomposición o proyectiva
{X}→{YZ} |= X}→{Y},{X}→{Z
Regal de union o aditiva
X}→{Y},{X}→{Z |= {X}→{YZ}
Regla pseudotransitiva
X}→{Y},{WY}→{Z |= {WX}→{Z}
Normalización
1FN
- Datos atómicos
- Todas las tablas deben tener una clave primaria
- Una tabla no debe tener atributos que acepten valores nulos
2FN
- Todo atributo no primo depende funcionalmente de todas las claves candidatas con dfs completas
3FN
- Ningún atributo no primo depende transitivamente de una clave candidata
FNBC (Forma Normal Boyce-Codd)
- Los unicos determinantes son las claves candidatas
T3 Modelo Entidad Relación
Un modelo entidad-relación (ER) es una herramienta de modelado utilizada para representar datos y sus relaciones en un sistema de información. Se utiliza principalmente en el diseño de bases de datos.
El modelo ER se suele representar gráficamente mediante diagramas ER, donde:
- Las entidades se representan con rectángulos.
- Los atributos se representan con óvalos conectados a sus entidades.
- Las relaciones se representan con rombos conectados a las entidades involucradas.
Este modelo es fundamental para el diseño lógico de bases de datos, ya que permite visualizar y estructurar los datos de manera clara y organizada.
Entidad
Representa un objeto o concepto del mundo real que tiene existencia independiente. Por ejemplo, un Cliente o un Producto.
Atributo
Describe propiedades o características de una entidad. Por ejemplo, un Cliente puede tener atributos como Nombre, Dirección y Teléfono.
Relación
Representa una asociación entre dos o más entidades. Por ejemplo, un Cliente puede tener una relación de Compra con un Producto.
T4 Paso de ER a MR
1: Tipos de entidad fuertes
- Por cada entidad fuerte se crea una relación que incluya todos los atributos de la entidad
- Se establece como clave primaria el identificador de la entidad
2: Tipos de entidad débiles
- Por cada entidad débil se crea una relación que incluya todos los atributos de la entidad
- Se establece como clave primaria el identificador de la entidad propietaria y el discriminante si existe
3: Tipos de relación binarios 1:1
- Escogemos una de las relaciones e incluimos como clave foránea la clave primaria de la otra
4: Tipos de relación binarios 1:N
- Incluimos como clave foránea en la entidad del lado N la clave primaria de la otra entidad
- Cualquier atributo de la relación se incluye como atributo de la primera entidad
5: Tipos de relación binarios N:N
- Se crea una relación que incluye como claves primarias y foráneas las claves primarias de las dos entidades
- Se incluyen los atributos propios de la relación en ella
6: Atributos multivaluados
- Se crea una nueva relación que incluirá el atributo además de la clave primaria de la entidad
- La clave primaria será la combinación de dicho atributo más la clave primaria de la entidad
7: Tipos de relación de grado mayor a 2
- Se crea una relación que incluye las claves primarias de cada una de las entidades involucradas más los atributos de la relación
- La clave primaria se forma con las claves primarias de las entidades de participación N
Resumen
| Entidad-Relación | Modelo Relacional |
|---|---|
| Tipo de Entidad | Relación |
| Tipo de Relación 1:1 o 1:N | Clave externa(o relación) |
| Tipo de Relación M:N | Relación con dos claves externas |
| Tipo de Relación n-aria | Relación con n claves externas |
| Atributo simple | Atributo de relación |
| Atributo compuesto | Atributos de relación |
| Atributo multivaluado | Relación y clave externa |
| Atributo clave | Clave primaria |
T5 Ficheros
Conceptos básicos de ficheros
- Los archivos se organizan como secuencias de registros
- Cada registro es similar a un struct en C con diferentes valores
- Una clave es un campo o conjunto de campos usados para identificar u ordenar los registros de un fichero
- Una clave externa se deriva de algunas características físicas del registro almacenado, como posición
- Una clave primaria es aquella clave tal que NO existen dos registros que puedan tener el mismo valor
- Los registros pueden ser de longitud fija o variable
Borrado de registros de longitud fija
Para optimizar el borrado almacenaremos en la cabecera del fichero la posición del primer registro borrado y usaremos el primer registro borrado para almacenar la posición del segundo, y así sucesivamente.
Borrado de registros de longitud variable
- Los registros se colocan en bloques
- Los bloques son pequeños lo que nos permite desplazar los registron en el borrado sin demasiado coste
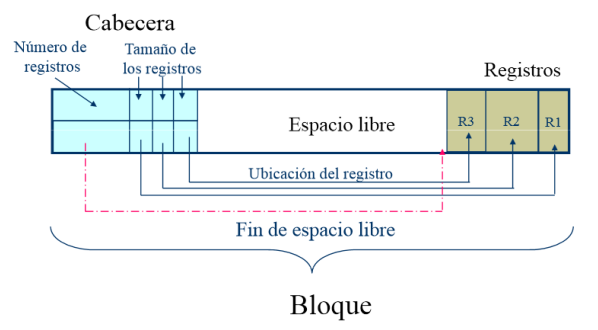
- Cada bloque contiene:
- El número de registros
- El espacio vacío
- Un array con la ubicación y el tamaño de cada registro
Tareas básicas sobre ficheros
- Añadir un nuevo registro
- Borrar un registro
- Leer todos los registros en cualquier orden
- Leer todos los registros en el orden de clave
- Leer un registro con un valor específico de clave
- Actualizar el registro actual
Características del medio físico
Los bloques físicos es la unidad de transferencia de disco a memoria
El factor de bloqueo es el número de registros lógicos por bloque físico
No existe una fórmula para calcular el factor de bloqueo adecuado
- Límite inferior viene impuesto por la necesidad de evitar un número excesivo de tranferencias de información cuando se lee secuancialmente
- Límite superior: tamaño del buffer de memoria principal o el tiempo para transmitir los datos
Organización de los regístros en archivos
Ficheros Montículo
Los registros se colocan en cualquier lugar en el que haya espacio suficiente (no se ordenan)
Ficheros Ordenados
Los registros se guardan según el valor de la clave
Ficheros de acceso directo (Hash)
En los ficheros de acceso directo los registros pueden ser accedidos utilizando el número de registro como clave externa.
De este modo el fichero es similar a un array unidimentional de tamaño fijo donde cada elemento del array es un registro y el índice del array el número de registros. A cada posición de ese imaginario array le denominamos slot.
La posición de un registro dado se deriva de su clave, aplicando sobre dicha clave una función hash.
Una buena función hash debe:
- Generar números de registros distribuidos uniformemente y aleatoriamente
- Pequeñas variaciones en el valor de la clave deben causar grandes variaciones en el valor hash
- Minimiza la creación de sinónimos (claves con el mismo hash)
Hash Extensible
La principal limitación de los ficheros de acceso directo es que su tamaño es fijo
Si cambiaramos el tamaño del fichero habría que cambiar la función de hash y la posición de todos los registros
Necesitamos un fichero de tamaño dinámico
Propiedades de un hash extensible:
- El fichero se expandirá automáticamente según las necesidades de alojamiento sin reorganizar muchos registros
- El fichero se contraerá cuando sea necesario, teniendo una probabilidad muy baja de que la carga del fichero sea inferior al 50%
- La estructura del fichero perimitirá la recuperación de un registro por su clave primaria con un acceso a disco
T5 Índices
Introcducción
Las estructuras de índices proporcionan caminos alternativos para acceder a los registros sin afectar a la posición física de los registros
Los índices ayudan en todo tipo de consultas, aunque en las consultas por igualdad en la clave del fichero, los ficheros hash son más eficientes
- Índice primario: Si tenemos un fichero ordenado, cuando el índice indexa la clave de ordenación del fichero de datos
- Índice sin agrupación: que se especifica sobre cualquier campo(s) que no es el de ordenación (clave). también llamado índice secundario
- Índice denso: Tiene una entrad de índice por cada valor existente en el campo(s) indexado
- Índice escaso (o disperso): Lo contrario de índice denso
Métrica de evaluación de índices
- Tipos de acceso soportados eficientemente
- Tiempo de inserción
- Tiempo de borrado
- Coste de espacio
Índices basados en árboles
Los índices basados en árboles proporcionan una mejora sobre la búsqueda binaria
Árboles heterogéneos
- Son aquellos donde cada nodo del árbol cotiene sólo un tipo de puntero
- Los punteros de los nodos hoja son de distinto tipo que los de los nodos no hoja
- Los punteros de los nodos hoja apuntan a los registros del fichero de datos, los demás apuntan a otros nodos
Árboles homogéneos
- Son aquellos en los que cada nodo contiene dos tipos de punteros, punteros a registros y punteros a otros nodos
- Todos los nodos son idénticos en estructura, los nodos hoja tienen punteros de a un registro y a un árbol vacío
Diferencias entre árboles homogéneos y heterogéneos
La longitud media de la búsqued será mayor en los árboles heterogéneos que en los homogéneos.
Esto es porque en los heterogéneos la búsqueqda siempre tiene que llegar a los nodos hoja.
El precio que se debe pagar, es el espacio necesario para el doble juego de punteros en cada nodo y algoritmos más complejos.
Árboles B
- Cada nodo puede alojar como mucho 2d valores del campo de indexación con sus punteros a datos y 2d+1 de árbol
- Ningún nodo, excepto el nodo raíz, puede tener menos de d valores del campo de indexación
- Todos los nodos hoja están en el mismo nivel
- Las nuevas entradas siempre se añaden en los nodos hoja
- Si el nodo que le corresponde a la entrada está lleno, se produce desbordamiento, y tenemos que redistribuir
- Se redistribuyen las entradas entre el nodo objeto de la inserción, su padre y un nodo hermano adyacente
- Si esto no es posible, el nodo se divide en dos nodos, con la entrada que sería el valor medio del nodo proporcionando al nodo padre
Árboles B+
Es un árbol heterogéneo
Los valores del campo de indexación están duplicados. Algunos de ellos deben aparecer duplicados en los nodos no hoja para quiar la búsqueda
Además de los punteros a datos, cada nodo hoja tiene un puntero al nodo hermano siguiente en la secuencia de nodos hoja
Claves duplicadas en Árboles B
- Considerar las entradas duplicadas igual que las entradas normales. Muchos gestores añaden un tributo adicional ficticio para considerarlas entradas distintas
- Tener una entrada por valor, que apunta a una lista de punteros, que finalmente son lso que apuntan al fuchero de datos
T6 Recuperación y Concurrencia
Estructuras de almacenamiento y sus operaciones
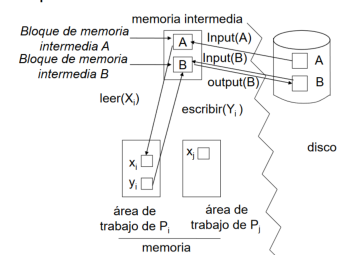
Almacenamiento volátil: Memoria principal o memoria caché. No sobrevive a la caida del sistema
Almacenamiento no volátil: Disco, cinta, memoria flash. Sobrevive a la caida del sistema
Almacenamiento estable: Muchas copias en distintod medios no volátiles. Sobrevive todos los fallos
Transacciones
- Tanto la recuperación ante fallos como el control del acceso concurrente se apoyan en el concepto de Transacción
- Una transacción es una unidad de ejecuciónde programa que accede, y posiblemente actualiza, a varios elementos de datos
- Una transacción debe ver una base de datos consistente
- Durante la ejecución de la transacción la base de datos puede ser inconsistente
- Cuando se compromete una transacción la base de datos debe ser consistente
- Se pueden ejecutar múltiples transacciones en paralelo
Propiedades
- Atomicidad: O todas las operaciones de la transación se reflejan correctamente en la base de datos o ninguna
- Consistencia: La ejecución de una transación en aislamiento preserva la consistencia de la base de datos
- Aislamiento: Cada transacción debe ignorar a las otras transacciones que se ejecutan concurrentemente con ella. Los resultados de las transacciones intermedias deben ocultarse de otras transacciones ejecutadas concurrentemente.
- Durabilidad: Tras la finalización con éxito de una transacción permanecen los cambios realizados en la base de datos, incluso si hay fallos en el sistema
Commit
Señala una finalización satisfactoria de la transacción, por lo que los cambios ejecutados por la transacción se pueden enviar con seguridad a la BD y no se desharán
Rollback
Señala que la transacción no ha terminado satisfactoriamente, por lo que deben deshacerse de los cabios o efectos que la transacción puediera haver aplicado a la BD
Estados
- Activa: la transacción permanece en este estado mientras se está ejecutando
- Parcialmente comprometida: después que se ha ejecutado la instrucción final
- Fallida: después de descubrir que la ejecución normal ya no puede llevarse a cabo
- Abortada: después de que la transacción se ha retrocedido y la base de datos restaurado a su estado anteriro al inicio de la transación
- Comprometida: después de terminación con éxito
Recuperación ante fallos
Recuperación: técnica que proporcionan los SGBD para poder recuperar la información cuando se produce un fallo
Tipos de fallos
Fallos de medios de almacenamiento: Caída dura
Fallos del sistema: Caída suave (se va la luz)
Errores de software: Puede hacer que la BD pierda consistencia
LOG
Secuencia de registros que mantiene un registro de las actividades de actualización de la BD. Un registro histórico se mantiene en almacenamiento estable
Concurrencia
Concurrencia: técnica que proporcionan los SGBD para permitir el acceso concurrente de varios usuarios a los mismos datos en el mismo instante de tiempo
Problemas
- Problema de pérdida de actualización
- Problema de lectura sucia
- Problema de lectura no repetible
- Problema de lectura fantasma
Planificación
Secuencia de las operaciones realizadas por un conjunto de transacciones concurrentes que preserva el orden de las operaciones en cada una de las transaciónes individuales
Planificación serie
Una planificación en la que las operaciones de cada transación se ejecutan consecutivamente sin que se entrelacen operaciones de otras transacciones
Serializable
Una ejecución de un conjunto de transacciones es serializable si producen el mismo resultado que alguna planificación serie.
Una ejecución concurrente solo se considera correcta si es serializable.
Sin embargo, dos planificaciones serie no tienen por que dar el mismo resultado final
Protocolos basados en bloqueos
Un bloqueo es un mecanismo para controlar el acceso concurrente a un elemento de datos
- Modo exclusivo: El elemento de datos además de leerse se puede escribir. Un bloqueo de este tipo se solicita con la instrucción bloquear-X
- Modo compartido: Los elementos de datos sólo se pueden leer. Un bloqueo de este tipo se solicita con la intrucción bloquear-S
La transacción puede realizar la operación sólo después de que se conceda la solicitud
-
Protocolo de bloqueo
Es un conjunto de reglas que siguen todas las transacciones cuando se solicitan o se libera n bloqueos. Los protocolos de bloqueo restringen el número de planificaciones posibles.
-
Protocolo de bloqueo de dos fases
Fase 1: Crecimiento. Las transacciones pueden conseguir , aumentar y liberar bloqueos
Fase 2: Decrecimiento. Las transaciones pueden liberar, disminuir pero no conseguir bloqueos
Garantiza seriabilidad
-
Protocolo de bloqueo riguroso de dos fases
Fase 1: Crecimiento. Las transacciones pueden conseguir , aumentar pero no liberar bloqueos
Fase 2: Decrecimiento. Las transaciones pueden liberar bloqueos
Garantiza seriabilidad
Prevención de interbloqueos
Cuando se detecta un interbloqueo se tendrán que retorceder algunas transacciones para romper el interbloqueo. Se debe selecionar como víctima aquella transacción que incurra en un coste mínimo
Puede ser un retroceso total o parcial, se suele optar por lo segundo porque es más efectivo solo retroceder lo necesario.
Se produce la inanición cuando siempre se elige a la misma transacción como víctima. Para impedirlo se debe incluir en el factor de coste el número de retrocesos
-
Esperar-Morir
- Si la transacción que llega es más antigua que la que ya está, la transacción que llega espera
- Si la transacción que llega es más joven que la que está, muere y libera los bloqueos
- Se vuelve a lanzar la transacción con el mismo timestamp
-
Herir-Esperar
- Si la transacción que llega es más joven espera
- Si la transacción que llega es más antigua hiere a la más reciente
- Se vuelve a lanzar la transacción herida con el mismo timestamp
Esquemas multiversión
Los esquemas multiversión matienen las versiones anteriores de los elementos de datos para aumentar la concurrencia. cada escribir(Q) con éxito tiene como resultado la creación de una nueva versión de Q.
Las operaciones leer no tienen que esperar nunca ya que se devuelve la versión apropiada inmediatemente.
La técnica más frecuente es la de marcas temporales.